
Robots.txt is a file that tells search engines crawlers to not crawl certain section or pages of a website. Robots.txt is a simple yet significant file that can control the fate of your website in SERP.
Robots.txt errors are amongst the most public SEO errors you’d typically find in an SEO audit report. Even the most seasoned Search Engine Optimization professionals are susceptible to robots.txt errors.
Which is why it’s important to get a deeper understanding of how robots.txt works.
By thoughtful the basics, you’ll be able to make the perfect robots.txt file that makes it easier for search engines to crawl and index your pages.

In this comprehensive guide, we’ll cover:
- What is robots.txt?
- Why is robots.txt important?
- How to find your robots.txt file?
- Robots.txt syntax
- How to create a robots.txt file?
- How does robots.txt Work?
- Robots.txt best practices
What is Robots.txt?
Robots.txt is a text file produced by website owners that instructs search engines crawler on how to crawl pages on your website. Otherwise, a robots.txt file tells search engines crawler where it can and cannot go on your website.
According to Google: Robots.txt Introduction and Guide | Google Search Central
Robots.txt is used frequently to manage crawler traffic to your site, and usually to keep a page off Google, dependent on the file type.
For instance, if there’s a specific page on your site that you don’t want Google to index, you can use robots.txt to block Googlebot from crawling that page.
If we disallow a page but we want to allow a subpage still we can do that,
Example:
Disallow: /menclothing
Allow: /menclothing/t-shirt
Allow: /menclothing/shirt
Why robots.txt Important?
Bots used by search engines are programmed to crawl and index web pages. You can choose which pages, folders, or the entire website should not be crawled by using a robots.txt file.

These can be handy in many different situations. Here are major situations you’ll want to use your robots.txt:
Block private pages from search engine crawlers: Use robots.txt to limit visitors’ access to your website’s secret pages. Your website’s staging versions and login page should not be accessible to the public. This is where you can utilize robots.txt to prevent other users from visiting specific websites.
Optimize your crawl budget: The amount of pages Googlebot will crawl each day is known as its crawl budget. A crawl budget issue could be the cause of your inability to have all of the crucial pages indexed. In this instance, you can maximize your crawl budget by preventing access to irrelevant pages via robots.txt.
Prevent crawling of duplicate content: Robots.txt can be used to prevent duplicate pages from ranking in search engine results pages (SERPs) if the same content is on several pages. eCommerce websites frequently have this problem, which is easily avoided by including a few straightforward directives in your robots.txt file.
Prevent resource files from appearing in SERPs: You can stop the indexing of resource files such as PDFs, pictures, and videos by using Robots.txt
Avoid server overload: To prevent sending too many requests to your website at once, you can set a crawl delay using robots.txt.
But, is robots.txt required?
Even if it is empty, a robots.txt file ought to be on every website. The robots.txt file is the first thing search engine bots look for when they visit your website.
The spiders receive a 404 (not found) error if none are present. While Google claims that a robots.txt file is not necessary for Googlebot to continue crawling a website, we think it is preferable for the first file a bot asks to load rather than resulting in a 404 error.
How to check your robots.txt file?
Website Name/robots.txt
Example https://theknowsea.com/robots.txt
It is really simple to locate your robots.txt file if you already have one.
Just type websitename.com/robots.txt in your web browser, and if your site has a robots.txt file, it should look somewhat like this:
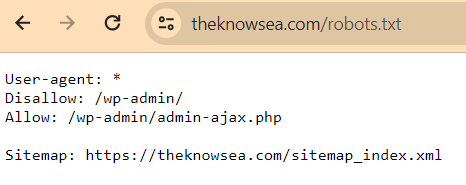
If your site does not have a robots.txt file, you will find an empty page.
Robots.txt Syntax
Before producing a robots.txt file, you need to be aware with the syntax used in a robots.txt file. Here are the 4 major common components you’ll notice in your robots.txt file:
User-agent: The web crawler you are providing instructions to has this name. The user-agent name varies throughout search engines. As a wildcard, an asterisk (*) can be used to apply rules to all user agent types.
Disallow: This is the directive used to instruct a user-agent not to crawl an exact URL. You can use a forward slash (/) to indicate the entire site.
Allow: This directive is used to instruct a user-agent to crawl a pages, even though its parent pages is disallowed.
Sitemap: This is the directive used to require the location of your XML sitemap to search engines.
Crawl-delay: This line specifies the minimum time delay (in seconds) that a crawler should wait between requests to the site, this can be useful to reduce server load.
Example:
- All user agents are addressed (User-agent: *).
- Crawling is disallowed for everything under “/private/” (Disallow: /private/).
- Crawling is allowed for everything under “/public/” (Allow: /public/).
- A crawl delay of 15 Sec. is submitted (Crawl-delay: 10).
Remember that not all web crawlers support all robots.txt directives, so it’s essential to check the documentation of specific crawlers for accurate information.
How to Create a Robots.txt File?
It’s simple to create a robots.txt file if your website doesn’t already have one. The robots.txt file can be created with any text editor like Notepad.
The TextEdit application can be used to create your robots.txt file if you use a Mac.
Launch the text document and begin inputting commands.
For instance, make a file called robots.txt that looks like this if you want Google to index every page of your website and only show the admin page.
User-agent: *
Disallow: /wp-admin/
Once you’re done entering all the directives, save the file as “robots.txt.”
You can also custom this free robots.txt generator by SEOptimer to make your robots.txt.
I strongly advise using a robots.txt generator to ensure that you don’t make any syntactical mistakes when generating your robots.txt file. Make sure that robots.txt is configured correctly, as even a minor syntax error can cause your site to be deindex.
When your robots.txt file is prepared, upload it to your website’s root directory.
Use an FTP client like Filezilla to place the txt file in the root directory of the domain.
For example, the robots.txt file of websitename.com should be accessible at websitename.com/robots.txt.
How does robots.txt Work?
You can use a basic program like TextEdit or Notepad to create a robots.txt file. Save it with the filename robots.txt and upload it to the root of your website as www.websitename.com/robots.txt —— this is where spiders will look for it.
A simple robots.txt file might look something like this:
User-agent: *
Disallow: /directory-name/
Google explains the meaning of each line in a group in detail in their help guide for creating the robots.txt file:
In their help file on writing robots.txt, Google provides a clear explanation of what each line in a group means within the robots.txt file:
Each group consists of multiple rules or instructions, one instructions per line.
A group gives the following information:
• Which folders or files the agent may access
• Which directories or files the agent cannot access
• To whom the group applies (the user agent)
I’ll explain more about the different directives in a robots.txt file next.
Robots.txt Instructions
Typical robots.txt syntax contains the following:
User-agent
The bot you are delivering orders to, such as Googlebot, Yahoobot, or Bingbot, is referred to as the user-agent. For various user agents, you can have different instructions. However, as demonstrated in the preceding section, using the * character represents a catch-all that includes all user agents. You can see a list of user agents here.
Disallow
The Disallow rule specifies the folder, file or even an entire directory to reject from Web robots access.
Robots.txt Best Practices
Once you have a basic understanding of robots.txt, let’s briefly go over some best practices to follow:
1. Robots.txt is a Case Sensitive
The file name robots.txt is case-sensitive. Thus, ensure that the file is named, “robots.txt” (and not robots.TXT, ROBOTS.TXT, Robots.Txt, etc.)
2. Place the Robots.txt File in the Main Directory
The robots.txt file needs to be located in your site’s main directory. Your robots.txt file won’t be found if it is stored in a subdirectory.
Bad:
websitename.com/page/robots.txt
Good:
websitename.com/robots.txt
3. Use Wildcards to Control How Search Engines Crawl Your Website
There are two wildcards you can use in your robots.txt file —the ($) wildcard and the (*) wildcard. The use of these robots.txt wildcards helps you control how search engines crawler your site. Let’s examine each of these wildcards:
($) Wildcard
A URL’s end is indicated by the wildcard ($). To prevent crawlers from indexing all PDF files on your website, for example, you should have something like this in your robots.txt file:User-agent: *
Disallow: /*.pdf$
(*) Wildcard
In your robots.txt file, you can use the (*) wildcard to address all user-agents (search engines). To prevent any search engine crawler from accessing your admin page, for example, your robots.txt file should look like this:
User-agent: *
Disallow: /wp-admin/
4. Use Comments for Future Reference
Developers and other team members who have access to the file can benefit from the comments in your robots.txt file. They can be referred to in the future as well.
Enter your remark after typing the hash key (#) in your robots.txt file.
Here’s an example:
# This blocks Googlebot from crawling yoursitename.com/directory1/
User-agent: googlebot
Disallow: /directory1/
Hash lines are ignored by web crawlers.
5. For every subdomain, make a different Robots.txt file.
Robots.txt files are needed for each subdomain. As such, you will need to create two separate robots.txt files if you have a section of your site hosted on a different subdomain.
Final Thoughts
Even though robots.txt is just a simple text file, it works well as an SEO tool. Robots.txt file optimization can improve both search engine visibility and indexability of your website.